Wednesday, September 11, 2013
 Concurrent Hardware and Atomicity & Independence
Concurrent Hardware and Atomicity & Independence
1Hardware¶
There are lots of different kinds of concurrent hardware.
- Our desktops or laptops most likely have more that 1 processor, maybe even 8 or more.
- Servers might have dozens, or hundreds.
1.1Basic Uniprocessor¶

Modern, pipelined and superscalar architecture (multiple functional units).
- Can issue and execute more than one instruction at a time.
- Low-level parallelism.
On this, we can do multithreaded programming thanks to context switching between threads. In effect, the threads are time-sliced.
Multiple threads can be useful for hiding latency. However, true parallelism is impossible with a basic uniprocessor.
1.1.1Cache¶
Notice the cache: it is an important part of modern computer architecture due to the locality principle.
- Locality Principle
- If a program accesses
x, odds are that it will accessxand nearby data soon.
However, multithreading interferes with locality because the data accesses of a certain thread interleave with the others'.
1.2Multiprocessors¶
There is now more than one processor, with some kind of shared memory; there is more than one way to set these processors up.
1.2.1SMP: Symmetric Multiprocessors¶
There are multiple separate processors, but they are all the same.
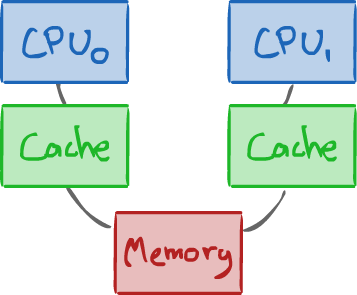
- Separate physical chips.
- Communication between them occurs over a bus.
Communication over a bus is somewhat slow. If the CPUs are on the same physical chip (i.e. multicore), we can get faster communication.
1.2.2CMP: On-Chip Multiprocessor¶
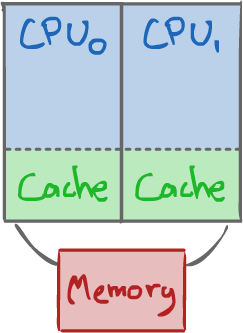
- Easier to share a cache.
- Fast communication between cores.
- Still, there are disadvantages: lots of programs are single-threaded.
If we don't have 2 active threads, half of the chip is idle. This is not an efficient use of resources!
1.2.3CMT/FMT: Coarse and fine-grained multithreading¶
Not really a multiprocessor; it's really just a single CPU with special hardware support for fast context-switching.
However, n-way CMT/FMT have support for n threads in hardware.
1.2.3.1CMT¶

- The hardware can context-switch easily (e.g. for each $x$ cycles).
- There is no sacrifice to single threaded performance.
- It gives the illusion of multithreading.
1.2.3.2FMT¶
There is fine grained switching on every cycle. It is also called "barrel processing".

It works like rotating a barrel where each slat represents a thread. This method exists because regular switching is easy to understand and manage.
1.2.3.3The example of Tera¶
Tera was an early multithreaded architecture for the Cray.
It followed an FMT design, but with no data cache. Notably, it took 70 cycles just to access memory.
One efficient way to avoid slowdowns was to have at least 70 threads to keep to CPU busy during the waits. With this many threads, access can start on the cycle of a certain thread, and once the context switching arrives to this thread again, the access has completed.
It gave a good overall throughput, but the performance of each individual thread was not very high.
1.2.4SMT: Simultaneous Multithreading¶
Susan Eggers et al. in 1994-95
- Supports single threaded and multithreaded programs.
- Allows true parallelism while also avoiding idleness.
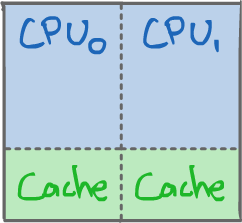
- There is a soft boundary between CPUs: If CPU0 is not using its resources (i.e. its respective functional units), then CPU1 can use them, and vice-versa.
- In the case of single threaded programs, they see one big CPU with twice the resources.
- Yet, multithreaded programs can run in parallel.
Theoretically, SMT (commercialized by Intel as Hyper-threading) works very well.
- However, early devices hiccups meant an hyper-threaded processor wasn't as good as 2 processors.
- It was also hardly even better than a single CPU.
- It is much improved now, but it is still not quite as good as two separate cores (maybe 1.5x).
1.3Practical example¶
Suppose we have a CPU device with:
- 2 ALUs (Arithmetic Logic Units)
- 2 FPUs (Floating-Point Units)
- 1 LSU (Load-Store Unit)
It can issue 2 instructions per cycle.
- Integer and floating-point operations take 1 cycle.
- Load and store operations take 2 cycles.
Three threads are running on the CPU with the following program:
| Thread 1 | Thread 2 | Thread 3 |
|---|---|---|
| 1. Add | 1. Load | 1. AddFP |
| 2. Load | 2. Add | 2. AddFP |
| 3. Add | 3. Add | 3. AddFP |
Where T1.3 depends on T1.2 and T2.2 depends on T2.1.
1.3.1Uniprocessor¶
There are 2 instruction per cycle and all threads are in order.
| Threads | Slot 1 | Slot 2 |
|---|---|---|
| Thread 1 | 1. Add | 2. Load |
| Thread 1 | - | - |
| Thread 1 | 3. Add | - |
| Thread 2 | 1. Load | - |
| Thread 2 | - | - |
| Thread 2 | 2. Add | 3. Add |
| Thread 3 | 1. AddFP | 2. AddFP |
| Thread 3 | 3. AddFP | - |
There were 8 cycles in total, but 7 slots were wasted.
1.3.2SMP/CMP (2 processors)¶
| Processor 0 Slot 0 | Processor 0 Slot 1 | Processor 1 Slot 0 | Processor 1 Slot 1 |
|---|---|---|---|
| T1: 1. Add | T1: 2. Load | T2: 1. Load | - |
| - | - | - | - |
| T1: 3. Add | - | T2: 2. Add | T2: 3. Add |
| T3: 1. AddFP | T3: 2. AddFP | - | - |
| T3: 3. AddFP | - | - | - |
There were 5 cycles in total, but 11 slots were wasted. It is an improvement on the number of cycles, but it is also more wasteful.
1.3.3FMT¶
| Threads | Slot 1 | Slot 2 |
|---|---|---|
| Thread 1 | 1. Add | 2. Load |
| Thread 2 | 1. Load | - |
| Thread 3 | 1. AddFP | 2. AddFP |
| Thread 1 | 3. Add | - |
| Thread 2 | 2. Add | 3. Add |
| Thread 3 | 3. AddFP | - |
There were 6 cycles in total, but only 3 slots wasted.
1.3.4SMT¶
| Processor 0 Slot 0 | Processor 0 Slot 1 | Processor 1 Slot 0 | Processor 1 Slot 1 |
|---|---|---|---|
| T1: 1. Add | T1: 2. Load | T2: 1. Load | - |
| - | - | - | - |
| T1: 3. Add | - | T2: 2. Add | T2: 3. Add |
| T3: 1. FPAdd | T3: 2. FPAdd | T3: 2. FPAdd | - |
There were 4 cycles in total, and 7 slots wasted. SMT's ability to share the CPUs' resources for a single thread was only useful once (in the last line, with T3).
2Atomicity and Independence¶
In concurrency, we are interested in the relations between one or more processors/threads. Still, it is possible to have 2 completely independent threads, but in such a case, concurrency is not very exciting.
2.1Definitions¶
- Read-set
- The read-set of a program/process/thread is the set of variables it reads, but does not write.
- Write-set
- The write-set of a program/process/thread is the set of variables it writes (and may read).
- Independent threads
- 2 processes/threads are independent if the write set of each is disjoint with the read and write set of the other.
- As such, 2 processes/threads are not independent if one writes data the other reads and/or also writes.
2.2What happens when processes interact?¶
For example, consider the line of code x = y = z = 0;.
After which Thread1 executes x = y + z; and Thread2 executes y = 1; z = 2;.
What is the final value of x? It depends on the order in which threads execute.
| Scenario 1 | Scenario 2 | Scenario 3 |
|---|---|---|
T1: x = y + z; |
T2: y = 1; |
T2: y = 1; |
T2: y = 1; |
T2: z = 2; |
T1: x = y + z; |
T2: z = 2; |
T1: x = y + z; |
T2: z = 2; |
Value of x: 0 |
Value of x: 3 |
Value of x: 1 |
Note: To interleave statements, we assume they either execute, or not. They are atomic.
- Atomic
- Indivisible. No partial state of the action is externally visible.
In fact, statements like x = y + z; are not usually atomic. They might look like a single line of code, but in fact, they decompose to a sequence of machine language instructions:
Load r1, [y] # Put the value of y in Register 1 Load r2, [z] # Put the value of z in Register 2 Add r3, r1, r2 # Add the values of Registers 1 and 2, and put the result in Register 3 Store r3, [x] # Store the value of Register 3 in x
Interleaving can occur between any machine instruction.
| Scenario 4 | Values |
|---|---|
T1 loads y into R1 |
R1 = 0 |
| T2 executes its instructions | y = 1, z = 2 |
T1 loads z into R2 |
R2 = 2 |
T1 adds R1 + R2 into R3 |
R3 = 2 |
T1 stores R3 into x |
x = 2 |