Wednesday, November 13, 2013
 OpenMP memory model, Java OpenMP and Flynn's taxonomy
OpenMP memory model, Java OpenMP and Flynn's taxonomy
1OpenMP memory model¶
OpenMP uses a weak memory model. Nothing is necessarily sequentially consistent unless we use the previously discussed synchronization constructs.
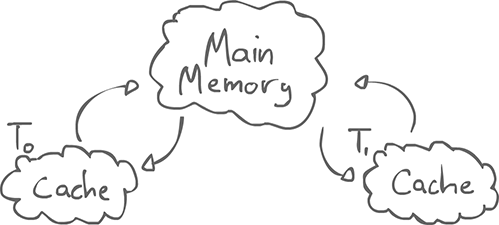
There is some idea of main memory, but each thread have their own cached copy of things, and communicate with main memory. They have a temporary (cached) view of main memory.
When x is read by a thread, if x is not in the cache, it loads it from main memory. If it is cached, it grabs the cached copy.
When x is written. The cached copy is updated, but it is commited at some undetermined time in the future. Lazily and non-determistically, x is written to memory.
That is to say, if the use of a variable is not atomic, there is no atomic gurantee at all. The use of flush(a, b, c) allows to invalidate any local cached copy of a, b and c. Any pending write to a, b and c is thus commited.
- 3 rules of flush
- 1) If the intersection of the flush sets (a, b, c) is non-empty, then the flushes must be seen in (some) sequential order by all threads.
- 2) If it is empty, there is no guarantee; the threads may observe these flush in different orders.
- 3) If a thread access/modifies a variable in a flush set, the access/modify and the flush must respect program order.
Atomic operations have an implicit flush set of the associated variables.
1.1Example¶
| Thread 0 | Thread 1 |
|---|---|
x = some local; |
- |
| - | some local = x; |
There is no guarantee on the order.
| Thread 0 | Thread 1 |
|---|---|
x = some local; |
- |
flush(x); |
some local = x; |
Now we know that x is going off to main memory, and there is some ordering. Still, no specific ordering.
| Thread 0 | Thread 1 |
|---|---|
x = some local; |
flush(x); |
flush(x); |
some local = x; |
Now, x is surely read from main memory. However, it does not guarantee that Thread 1 reads what Thread 0 wrote. It's a bit like having the volatile keyword on x.
// Crude critical section algorithm turn[id] = 1; if (turn[(id + 1 % 2)] == 0) CS(); // It's possible that both thread manage to set their turn variable at the same time // Here's what it looks like in OpenMP // Thread 0 // Thread 1 atomic (b=1); atomic(a = 1); flush(b); /* Commit b */ flush(a); flush(a); /* Invalidate cache of a */ flush(b); atomic (tmp = a); /* Read a */ atomic (tmp = b); if (tmp == 0) if (tmp == 0) CS(); CS();
This is not guaranteed to work. There is guarantee of program order: the compiler/hardware/runtime can reorder things and take the first three lines of each thread and put it at the end. Despite the well-ordering of the three lines, both threads will end up in the critical section.
// Correct way // Thread 0 // Thread 1 atomic (b = 1); atomic (a = 1); flush (a, b); flush(a, b); atomic (tmp = a); atomic(tmp = b); if (tmp == 0) if (tmp == 0) CS(); CS();
Now that the flushes include both a and b, the flush sets intersect. We get full ordering in each thread. But it is also still possible that neither thread enters the critical section (won't ensure progress).
2Java OpenMP¶
We can put OpenMP directives into Java, but Java introduces some weird behaviour. At the research level, there exists JOMP and JAMP. Neither of them gives a full OpenMP, and they both have a peculiar bahaviour.
2.1Private-first objects¶
Java is an object oriented language, and gives a lot of abstraction over low-level programming.
In OOP, the first-private property of objects (their reference, really) does not hold. If we have an object x and declare it first-private, while we want each thread to have their own copy, they actually end up merely having their own copy of a reference to the same object.
In C++, there are copy constructors, which define exactly how the copy is instantiated. In Java, there is the clone() method which any object that implements Cloneable must have. We still end up with the idea of a deep vs shallow copy. By default, the copy is shallow, but it can be customized to be deep instead.
2.2Flush¶
Java does not have flush. There already is some kind of flush in Java with volatile and synchronized blocks. We know with the Java specs that it implies well-ordering of the threads. However, flush(a, b, c); implies ordering with the intersection. By merely declaring a, b and c, there is no such ordering.
2.3Existing threads¶
How do Java threads interract with OpenMP threads? Can OpenMP threads create Java threads and vice-versa? Exceptions are not part of OpenMP, yet they are an integral part of Java. What happens when an OpenMP thread throws an exception?
3Flynn's Taxonomy¶
1966, a standard way of thinking about concurrent programs; a way to organize different concurrent systems
Flynn's taxonomy. separates the instructions from the data. In a sequential program, we have a single instruction stream, and a single data volume. It's SISD.
- SISD
- Single instructions, single data; Sequential programs
- MIMD
- Multiple instructions, multiple data
- SIMD
- Single instructions, multiple data; GPUs and vector processing
- MISD
- Multiple instructions, single data; not used much, but good for fault-tolerance (redundancy)
- SPMD
- Single program, multiple data
- MPMD
- Multiple programs, multiple data
In the case of SPMD and MPMD, the instructions are executed at different rates. This is closer to what we have nowadays.
#pragma omp parallel for
for ( ... ) {
// Same program
// Different data for each thread
}
// SPMD execution model
There are languages that exclusively based on the idea of SPMD.
4PGAS languages¶
PGAS languages are also based on a uniform paradigm defining how memory is organized. PGAS stands for "Partitioned Global Address Space". We end up with something between the flexibility of Java and the rigidity of SPMD.
The goal is to take advantage of locality.
Many PGAS lanagues make use of the SPMD paradigm, but not all of them. The basic idea is to divide memory:
| CPU0 | CPU1 | CPU2 | CPU3 |
|---|---|---|---|
| Shared | Shared | Shared | Shared |
| ------ | ------ | ------ | ------ |
| Private | Private | Private | Private |
4.1Private and shared¶
There is some private data for each CPU, but there is also some shared data with some light boundaries between things. The idea is to make use of locality as a performance boost. The shared data is accessible by any CPU, but it's still proper to one particular CPU. The principle is also called affinity.
private int x; // (many) x = Thread.id; // Each thread puts their own thread id in their own x shared int y; // (one) y = Thread.id; // Whichever thread writes last will have its value in y
4.1.1Arrays¶
Since there is only one copy of y, where does it live? Different languages do it differently. For some kind of data it even becomes really important. For example, with arrays, we can control where the shared data live:
| Scheme | CPU0 | CPU1 | CPU2 | CPU3 |
|---|---|---|---|---|
| Block | a[0]; |
a[2]; |
a[4]; |
a[6]; |
| - | a[1]; |
a[3]; |
a[5]; |
a[7]; |
| Cyclic | a[0]; |
a[1]; |
a[2]; |
a[3]; |
| - | a[4]; |
a[5]; |
a[6]; |
a[7]; |
For different algorithms, some scheme will make more sense. There is also an hybrid scheme where blocks and cyclic. Whichever scheme is chosen, the algorithms will still work. However, to get the best performance, the right affinity has to be chosen. That is, every thread can access everything in the shared data, but anybody can access anything at the same speed.
4.1.2Pointers¶
There are different rules as to what pointers can point that. For example, a private pointer can point to private data, which is trivial and usually allowed. There can also be a shared pointer to shared data which makes sense too.
There can also be private pointers that point to share data and even have them point to the same area. However, a shared pointer to some private data does not make much sense and is usually disallowed.
4.2The Titanium language¶
Katherine Yelick et al
The languages is syntactically based on Java, but compiles down to C, and so machine code. Basically, it does not use a virtual machine.
It uses the SPMD memory model and does not give access to Java threads the same way OpenMP on Java does.
4.2.1Features added¶
There is a rich API with multidimensional arrays, iterators and sub-arrays. There is the concept of an immutable object in which case sharing is easy. There is a templating system, and operators can be overloaded.
4.2.2Global barrier¶
Since Titatinum has an SPMD paradigm, a chunk of code can be declared parallel in which case all the threads end up executing the same code. In such a section, a barrier can be introduced to make all the threads must get there before any can leave.
However, this has some interesting complications (that can happen in OpenMP as well). The barrier may be accessed conditionally:
if (Ti.numProc() % 2 == 0) { Ti.barrier(); }
In this case, the barrier is partial, and all the threads catching it end up stuck.
if (Ti.numProc() % 2 == 0) { Ti.barrier(); // Some barrier } else { Ti.barrier(); // Some barrier (not the same) }
Should this work, or not? In this case, all the thread end up reaching some barrier. Let's say this is okay.
if (Ti.numProc % 2 == 0) { Ti.barrier(); Ti.barrier(); // Called twice } else { for (int i = 0; i < 3; i++) { if (i % 3 < 2) Ti.barrier(); } }
What we have in this case, is half of the threads are getting two barriers. The other half gets two barriers as well, but in a less obvious way. Is this equivalent?
If we want all these things to work, we can make it very difficult to understand by blurring the definition of a barrier.
if (x) // private variable x Ti.barrier();
In Titanium, if all the threads see the same value of x, they all hit the same barrier. One way to guarantee that is the single keyword.
4.2.3Single annotation¶
single int x; // Every thread has the same value in `x`
We can also annotate methods single meaning that every thread is guaranteed to execute a method.
if (exp)
x = exp;
x is single value if exp is a constant. exp can also be a broadcast, or a function of single value.
int single step = 0; int single max = 0; for (step < max, step ++) // Some calculation Ti.barrier(); // Update the whole array Ti.barrier(); }
We end up with a program with epochs of calculation. We need to be sure that step and max are the same across the threads, or the number of iteration would not be the same. The single keyword enforces that
4.2.4Other features¶
Point<N>- An n-dimensional vector of integers. Meant to represent an index in a n-dimensional array. E.g.
Point<2> a = [1, 2]; Domain<N>- Set of
Point<N>Usually used to define grouping of array elements.
4.3The X10 language¶
Has APGAS: Asynchronous Partitioned Global Address Space.
X10 follows the model a bit differently.
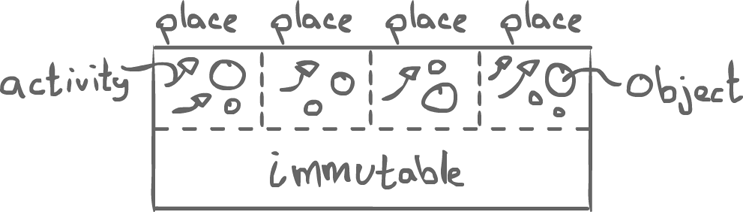
Access is possible amongst different places. Inside the places, there are threads and objects. The activities of a certain place can only update the objects of their own place. In the shared area, there is immutable data.
Activities can access local data, as well as distant data, through copying. To update remotely, a new activity is started at the remote place. There is also a mechanism allowing to migrate objects.
There is a version of X10 that compiles basically to C++, and then to binary, but there is also a version compiling to Java, and thus running in a JVM.